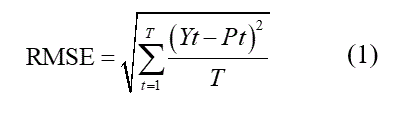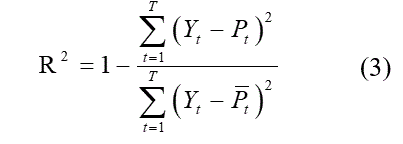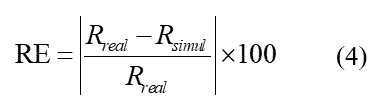INTRODUCCIÓN
El
control del tráfico en las zonas urbanas es cada vez más con el crecimiento
exponencial del número de vehículos. La ampliación de la red de carreteras para
acomodar el aumento del número de vehículos no es una opción socialmente viable
y es esencial aumentar la utilización de la infraestructura existente mediante
una regulación adecuada del flujo de tráfico. Los semáforos se introdujeron
para controlar el flujo del tráfico, mejorando así la seguridad de los
usuarios. Sin embargo, estos crean cuellos de botella para el flujo de tráfico
en los carriles que no tienen derecho de paso durante una fase específica y
optimización de los tiempos de las señales para reducir el retraso global de
todos los vehículos en la intersección. Con ello la optimización puede realizarse
fuera de línea (programada previamente) o en línea (adaptativa) (Balaji
et al., 2010, p. 177).
La
ciudad de Jaén se encuentra actualmente experimentando un crecimiento constante
en su población y en el número de vehículos que circulan por sus calles, lo
cual ha generado un problema generalizado en todo el país: la congestión del
tráfico. Esta situación refleja una gestión deficiente por parte de las
autoridades actuales, agravada por los cambios en el sistema de transporte. Es
crucial abordar este problema de manera específica, enfocándonos en todas las
áreas que presentan deficiencias en lugar de generalizar. Un ejemplo claro de
esto son las intersecciones en la ciudad, las cuales sufren de congestión,
falta de control, problemas de seguridad, altos índices de accidentes y bajos
niveles de servicio. En este contexto, se llevó a cabo un análisis enfocado en
las intersecciones semaforizadas de Jaén, con el propósito de mejorar la
circulación en el entorno urbano.
Ante
esta problemática se emplearon algoritmos de predicción RandomForest, support
vector machine (SVM), KNeighbors, Multi-Layer Perceptron (MLP) y Gradient
Bossting, mediante la metodología Knowlegde Discovery Databases (KDD) con sus
fases: etapa de selección, preprocesamiento, transformación, minería de datos e
intervención y evaluación de datos, el uso del lenguaje de programación Python,
las bibliotecas Sklearn, Numpy, Pandas, Seaborn, Scikit-learn y la interfaz
Jupyter Lab, y Visual Studio para crear un interfaz intuitiva para el usuario,
para calcular y reducir las demoras en las intersecciones.
El
objetivo de la investigación fue realizar la propuesta de un sistema adaptativo
para intersecciones semaforizadas en la ciudad de Jaén, mediante el diagnostico
de dos intersecciones, parámetros, diseño de modelos mediante algoritmos que
permitan la sustentabilidad y viabilidad del tránsito, elaborando un programa con
una interfaz gráfica intuitiva basado en los datos de representación del
algoritmo, que calcule y reduzca las demoras.
MATERIALES
Y MÉTODOS
Metodología
Se llevó a cabo la recopilación de
datos mediante la grabación de videos en ubicaciones estratégicas dentro de las
áreas de estudio. Posteriormente, se recopiló información acerca de las
características geométricas, de tráfico y semafóricas de cada cruce, con el
propósito de obtener los parámetros necesarios para el análisis. Se desarrollaron
los algoritmos para la demora y el ciclo óptimo, tomando en consideración las
fases de la metodología KDD, así como los métodos de Webster y HCM. A través de
los algoritmos desarrollados, se llevó a cabo la creación y ejecución de un
programa utilizando el entorno de Visual Studio y el lenguaje de programación
Visual Basic .NET (VB.NET), con el objetivo de calcular y reducir los tiempos
de demora y ciclo óptimo, y en consecuencia, mejorar el nivel de servicio en
cada cruce.
Zona de estudio
Se seleccionaron dos intersecciones
semaforizadas básicas en la ciudad, localizadas en un área comercial, en el
Noroeste de la localidad de Jaén, con volúmenes vehicular variantes. El diagnóstico
realizado en esta área de estudio: la primera intersección en las calles Simón
Bolívar con Pardo Miguel, y una segunda intersección en la avenida Villanueva
Pinillos con la calle Simón Bolívar. Estas intersecciones forman parte de una
vía colectora principal y, en otra medida, de una vía local en Jaén (Ver Figura
1).
Figura
1
a)
intersección de calles Pardo M. y Simón B., b) Av. Villanueva P. y calle Simón
B.

Matriz de datos
Se creo una matriz de datos con 577
instancias y 16 variables extraídas de información científica; las variables
fueron ancho de vía (ANV), tiempo de semáforo en verde (T), Flujo de saturación
(ST), tiempo de ciclo (C), coeficiente de verde (Y), grado de saturación (X),
flujo del carril (Q) y tiempo de demora (DM), Número de Fases (NF), Número de
carriles (NC), Factor de equivalencia (FE), Flujo vehicular directo (q), Flujo
de saturación de la intersección (Yi), Tiempo total perdido por ciclo (P),
Flujo peatonal (FP), Tiempo de ciclo optimo (Tco) (Ver Tabla 1).
Tabla 1
Descripción de las variables recolectadas
|
Variable
|
Descripción
|
Unidad
|
Tipo
|
|
Ancho de la vía
|
Es la
medida horizontal de la superficie de la carretera, desde un lado al otro.
|
m
|
Continua
|
|
Tiempo de semáforo en verde
|
Es el
intervalo temporal durante el cual el semáforo permite el flujo
ininterrumpido de vehículos en una dirección
|
s
|
Continua
|
|
Saturación
|
Es el
volumen máximo por hora que puede pasar por una intersección con un carril en
verde fijo durante una hora.
|
veh/h/carril
|
Continua
|
|
Tiempo del ciclo
|
Es la
duración completa de un ciclo de operación de un conjunto de semáforos en una
intersección.
|
s
|
Discreta
|
|
Coeficiente de tiempo de verde
|
Representa
la proporción del tiempo total de un ciclo de semáforo cuando está en fase
verde.
|
-
|
Continua
|
|
Grado de saturación
|
Representa
la proporción del flujo vehicular actual en comparación con la capacidad
máxima de la carretera o intersección.
|
-
|
Continua
|
|
Flujo del carril
|
Es la
cantidad de vehículos que pasan por un carril de una carretera o una vía en
un período de tiempo específico
|
Veh/h
|
Continua
|
|
Tiempo de demora
|
Es el
período de tiempo adicional que un vehículo experimenta al pasar por un punto
específico en la red de transporte.
|
s
|
Discreta
|
|
Número de Fases
|
Es la
cantidad de secuencias distintas de movimientos vehiculares y peatonales que
son controladas por el ciclo completo del semáforo.
|
-
|
Discreta
|
|
Número de carriles
|
Es la cantidad
de pistas disponibles para el flujo de vehículos en una carretera.
|
-
|
Discreta
|
|
Factor de equivalencia
|
Es el
valor que se asigna al flujo para movimientos rectos (1) y derecha o
izquierda (1.2).
|
-
|
Continua
|
|
Flujo vehicular directo
|
Es el
flujo de automóviles directos, que no dan vuelta, equivalentes por hora
|
Veh/h
|
Continua
|
|
Flujo de saturación de la intersección
|
Es la
máxima tasa de vehículos que puede pasar a través de una intersección
regulada por semáforos.
|
Veh/h
|
Continua
|
|
Tiempo total perdido por ciclo
|
Es la
multiplicación del número de fases por el tiempo de ámbar (3 a 4 s)
|
s
|
Discreta
|
|
Flujo Peatonal
|
Es la
cantidad de personas que pasan durante un periodo determinado de tiempo
|
-
|
Discreta
|
|
Tiempo de ciclo optimo
|
Es el intervalo
de tiempo más eficiente y equitativo que maximiza la capacidad y minimiza las
demoras en una intersección regulada por semáforos.
|
s
|
Discreta
|
La Tabla 2, muestra la estadística
descriptiva de todas las variables de la base de datos, la variable "ANV"
tiene un promedio de 5.73 con una desviación estándar de 1.05. La variable
"T" exhibe un promedio de 19.84 con una desviación estándar de 4.33,
mientras que "ST" presenta un promedio de 2968.29 con una desviación
estándar de 602.02. Similarmente, la variable "C" tiene un promedio
de 73.72 con una desviación estándar de 19.92. Las variables "Y" y
"X" muestran promedios de 0.282 y 1.94 respectivamente, con
desviaciones estándar de 0.07 y 1.01, y rangos de valores entre 0.158 y 0.441
para "Y", y entre 0.072 y 4.36 para "X". Por otro lado,
"Q" tiene un promedio de 1519.23 con una desviación estándar de
722.67, con valores que oscilan entre 64.51 y 2200. "DM",
"NF", "NC", "FE", "q", "Yi",
"P", "AP" y "Tco" exhiben promedios de 46.92,
5.13, 2.49, 1.14, 584.99, 0.325, 20.52, 37.53 y 60.47 respectivamente, con
desviaciones estándar y rangos de valores específicos para cada variable.
Tabla 2
Estadística
de las variables de la base de datos
|
Variable
|
Cantidad
|
Promedio
|
Desviación Estándar
|
Mínimo
|
25%
|
50%
|
75%
|
Máximo
|
|
ANV
|
577
|
5.73
|
1.05
|
4
|
5
|
6
|
7
|
7
|
|
T
|
577
|
19.84
|
4.33
|
10
|
16
|
19
|
23
|
29
|
|
ST
|
577
|
2968.29
|
602.02
|
1978.35
|
2536.95
|
3150
|
3675
|
3675
|
|
C
|
577
|
73.72
|
19.92
|
38
|
55
|
90
|
92
|
95
|
|
Y
|
577
|
0.282
|
0.07
|
0.158
|
0.237
|
0.283
|
0.321
|
0.441
|
|
X
|
577
|
1.94
|
1.01
|
0.072
|
1.18
|
2.05
|
2.61
|
4.36
|
|
Q
|
577
|
1519.23
|
722.67
|
64.51
|
902
|
2000
|
2010
|
2200
|
|
DM
|
577
|
46.92
|
27.27
|
8.03
|
19.67
|
49.78
|
69.33
|
107.29
|
|
NF
|
577
|
5.13
|
2.92
|
1
|
3
|
5
|
8
|
10
|
|
NC
|
577
|
2.49
|
1.12
|
1
|
1
|
2
|
3
|
4
|
|
FE
|
577
|
1.14
|
0.091
|
1
|
1
|
1.2
|
1.2
|
1.2
|
|
q
|
577
|
584.99
|
366.17
|
16.8
|
252.15
|
593.5
|
803.6
|
1399.20
|
|
Yi
|
577
|
0.325
|
0.203
|
0.009
|
0.140
|
0.330
|
0.446
|
0.777
|
|
P
|
577
|
20.52
|
11.66
|
4
|
12
|
20
|
32
|
40
|
|
AP
|
577
|
37.53
|
7.42
|
21
|
31
|
38
|
43.75
|
50
|
|
Tco
|
577
|
60.47
|
39.99
|
11
|
30
|
51
|
80.75
|
213
|
Knowledge
Discovery in Databases
Etapa de selección
Para la
selección de los atributos, se analizó la distribución de cada variable. A
continuación, se utilizó la biblioteca Sklearn en la interfaz Jupyter Lab y se
ejecutó el algoritmo "RandomForest", que evalúa el valor de las
variables midiendo la ganancia relativa a la variable de salida utilizando el
comando "model.feature_importances_". Después de realizar el proceso
de clasificación de atributos, se procedió a la elección de las variables cuyo
peso superó el umbral de 0.5 (Ver Tabla 3).
Tabla 3
Variables
seleccionadas que proporcionan la mayor información
|
Variable
|
Símbolo
|
Peso
|
|
Ancho de la vía
|
ANV
|
0.63
|
|
Tiempo de semáforo en verde
|
T
|
0.52
|
|
Saturación
|
ST
|
0.65
|
|
Tiempo del ciclo
|
C
|
0.92
|
|
Coeficiente de verde
|
Y
|
-0.80
|
|
Grado de saturación
|
X
|
0.93
|
|
Flujo del carril
|
Q
|
0.85
|
|
Número de Fases
|
NF
|
0.76
|
|
Flujo vehicular directo
|
q
|
0.62
|
|
Flujo de saturación de la intersección
|
Yi
|
0.63
|
|
Tiempo total perdido por ciclo
|
P
|
0.76
|
Preprocesamiento y
limpieza
Durante la fase
de recolección de datos, es habitual encontrar la matriz de datos con
instancias nulas o que presentan anomalías, lo que introduce ruido en el
proceso de extracción de conocimientos. Para resolver este problema, se aplicó
un procedimiento de limpieza de datos con el fin de mejorar su calidad. Este
proceso se realizó empleando el lenguaje de programación Python, mediante la
interfaz Jupyter Lab junto con las bibliotecas Numpy, pandas y seaborn.
Transformación y
reducción
Se procedió a la
identificación de atributos con mayor representación de datos asociados al
tiempo de demora y ciclo optimo, empleando métodos de transformación destinados
a la disminución del número efectivo de variables. Asimismo, se llevaron a cabo
estrategias para la obtención de representaciones invariables respecto a los
datos mediante el empleo de técnicas estadísticas (Ver Tabla 4).
Tabla 4
Grupo de
variables de acuerdo a su importancia
|
Grupo
|
Variables
|
|
MP_1
|
Ancho de
la vía, Tiempo de semáforo en verde, Saturación, Tiempo del ciclo,
Coeficiente de verde, Grado de saturación, Flujo del carril
|
|
MP_2
|
Número de
FasesFlujo vehicular directo, Flujo de saturación de la intersección, Tiempo
total perdido por ciclo
|
|
MP_3
|
Ancho de la vía Tiempo del ciclo, Coeficiente
de verde, Grado de saturación, Flujo del carril
|
|
MP_4
|
Número de Fases, Flujo de
saturación de la intersección, Tiempo total perdido por ciclo
|
|
MP_5
|
Tiempo del ciclo, Coeficiente de
verde, Grado de saturación, Flujo del carril
|
Minería de datos
Se empleó el
lenguaje de programación Python, mediante la interfaz de JupyterLab junto con
el paquete Scikit-learn 1.1.2, diseñado específicamente para aplicaciones de
aprendizaje automático en Python. Este engloba una amplia gama de algoritmos de
aprendizaje automático, que abarcan técnicas supervisadas y no supervisadas,
presentadas de forma cohesionada a través de una interfaz uniforme y centrada
en las tareas. Los
algoritmos de predicción empleados para el entrenamiento y la extracción de
patrones fueron RandomForest, support vector machine (SVM), KNeighbors,
Multi-Layer Perceptron (MLP) y Gradient Bossting. Estos se caracterizan por
sus tres componentes de representación del conocimiento, evaluación y búsqueda,
mantienen un equilibrio, minimizando el sesgo sin afectar a la varianza,
adaptándose a diversos tipos de datos. Posteriormente, se configuraron los
hiperparámetros, como se indica en la Tabla 5, para garantizar la optimización
del rendimiento y la generalización del modelo.
Tabla 5
Configuración de los hiperparámetros de los algoritmos
|
Algoritmo
|
Hiperparámetros
|
|
RandomForest
|
n_estimators = 50, max_depth = None, min_samples_split
= 3, min_samples_leaf=2, random_state=42
|
|
Support Vector Machine
|
Kernel = rbf, C =1.0, Epsilon = 0.1, Gamma
= scale
|
|
KNeighbors
|
n_neighbors = 5, weights = uniform, algorithm
= auto
leaf_size
= 30
|
|
Multi-Layer Perceptron
|
hidden_layer_sizes = 100 activation = relu,
solver = adam, alpha = 0.0001, learning_rate = constant,
max_iter = 100
|
|
Gradient Bossting
|
n_estimators = 10, learning_rate = 0.2, max_depth
= 2, min_samples_split = 4, min_samples_leaf = 1, subsample = 1.0
|
Intervención y evaluación de datos
Tras el
entrenamiento de los grupos MP_1, MP_2, MP_3, MP_4 y MP_5 con la base de datos
adquirida y los modelos de minería, se llevó a cabo un análisis comparativo de los resultados predichos frente a
los valores reales utilizando métricas de rendimiento, error cuadrático medio
(RMSE), cuadrados totales del error (SSE), coeficiente de determinación (R2)
y error relativo (RE), ver ecuaciones (1)-(4).
Programa
Se
desarrolló el programa JJ22, empleando la máquina virtual Framework .net, el
Entorno de desarrollo integrado o IDE (Integrated Development Enviroment) de
Visual Studio Community 2022 y el lenguaje de programación Microsoft Visual
Basic .NET (VB.NET). Generando la interfaz con
las herramientas de editor de iconos, y personalización de controles de Visual
Studio, se agregaron los elementos "Archivo", "Configurar",
"Registros", "Informes", "Vehículos",
"Turno", "Procesar" y “Fases”. Estos elementos tienen
diferentes funcionalidades para la gestión y control de intersecciones
semaforizadas, incluyendo la configuración de parámetros, el registro de datos,
la generación de informes y la gestión de vehículos y turnos (Ver Figura 2).
Figura 2
Creación de sub ventanas en cada pestaña del programa

RESULTADOS
Caracterización
y análisis del accionar de las intersecciones
El análisis
inicial para validar el algoritmo requirió examinar la presencia y eficacia de
la señalización en dos intersecciones semaforizadas consideradas como puntos
base en la ciudad. Estas intersecciones (Figura 3), fueron: la primera intersección
a) calles Simón Bolívar con Pardo Miguel, con coordenadas UTM Norte (N):
9368514 y Este (E): 742668. y la segunda intersección está en b) la avenida
Villanueva Pinillos con la calle Simón Bolívar, con coordenadas UTM Norte (N):
9368578 y Este (E): 742834.
Figura 3
Control y señalización en las dos intersecciones a) y b)


Matriz
de datos
La matriz de
datos fue conformada por 577 instancias y 16 variables extraídas de información
científica, proporcionando una base sólida para la investigación. La primera
base de datos se recolecto en función de las variables que influyen en el
tiempo de demora y la segunda en función de variables que influyen en el tiempo
de ciclo optimo (Ver Figura 4). Estas incluyen las características las cuales abarcan
un espectro integral de factores relevantes para estudio del tránsito en
intersecciones.
Figura 4
Base de datos de las
variables que influyen en el tiempo de demora y tiempo de ciclo óptimo
Metodología
KDD
Después de
entrenar y validar los modelos MP_1, MP_2, MP_3, MP_4 y MP_5, distribuidos en
dos grupos para determinar el tiempo de demora (MP_1, MP_3 y MP_5) y para el
cálculo del tiempo de ciclo óptimo (MP_2 y MP_4) con los algoritmos RandomForest,
Support, Vector Machine (SVM), KNeighbors, Multi-Layer Perceptron (MLP) y
Gradient Bossting se obtuvo los siguientes estadísticos R y R2.
Modelo
MP_1 y MP_2
El modelo MP_1 se
conformó por el Ancho de la vía, Tiempo de verde, Saturación, Tiempo del ciclo,
Coeficiente de verde, Grado de saturación, Flujo del carril. El MP_2 por el Número
de Fases, Flujo vehicular directo, Flujo de saturación de la intersección,
Tiempo total perdido por ciclo.
Tabla 6
Estadísticos
de precisión de los algoritmos de los modelos
|
Algoritmos
|
MP_1 (R)
|
MP_1 (R2)
|
MP_2 (R)
|
MP_2 (R2)
|
|
RandomForest
|
0.998
|
0.995
|
0.998
|
0.996
|
|
Support, Vector Machine
|
0.846
|
0.689
|
0.638
|
0.325
|
|
KNeighbors
|
0.985
|
0.970
|
0.943
|
0.884
|
|
Multi-Layer Perceptron
|
0.895
|
0.788
|
0.957
|
0.893
|
|
Gradient Bossting
|
0.991
|
0.964
|
0.983
|
0.910
|
La Tabla 6, presenta los
resultados de la aplicación de diferentes algoritmos de aprendizaje automático
al conjunto de datos, evaluados mediante las métricas R y R2. Se
observa que el MP_1 con el algoritmo RandomForest ha logrado un rendimiento
alto, con valores de 0.998 y 0.995 para R y R2, y para el MP_2 también
obteniendo valores de 0.998 y 0.996 para R y R2 respectivamente (Ver
Figura 5).
Figura
5
Precisión
de los algoritmos del modelo MP_1 y MP_2
Validación
de los algoritmos
Durante
el proceso de entrenamiento, se observó que los modelos con alta precisión
fueron el MP_1, empleando el algoritmo RandomForest, con un R2 de
0.995 para la estimación del tiempo de demora, y el MP_2, con el algoritmo
RandomForest, con un R2 de 0.996 para la determinación del tiempo de
ciclo óptimo (Ver Figura 6). Estos algoritmos se utilizaron para el desarrollo
del programa, se guardaron en formato “joblib” y se exportaron a la extensión
“ONNX”.
Figura 6
Validación de los cinco algoritmos del modelo

Interfaz de inicio del
Programa
La
interfaz contiene un conjunto de funcionalidades: la gestión de archivos,
configuraciones personalizadas, registro de datos, generación de informes,
configuración del tipo de vehículo, turnos y la gráfica de la intersección la
cual muestra las condiciones asignadas para el análisis, mostrando los datos de
flujo vehicular según el sentido, Norte (N), Sur (S), Este (E) y Oeste (O), y
el nombre de las calles (Ver Figura 7).
Figura 7
Pestañas multifuncionales del programa JJ22

Determinación del tiempo
de demora
Para
determinar el tiempo de demora, se accede a la pestaña de informes y se elige
la sección denominada 'Demora actual'. A continuación, se selecciona el ícono
de procesamiento, que utiliza el algoritmo previamente entrenado considerando
las variables más significativas. Los resultados obtenidos se presentan en una
sub ventana para cada sentido y en la parte inferior se proporciona información
detallada sobre la demora total de la intersección y el nivel de servicio (Ver
Figura 8).
Figura 8
Cálculo del tiempo de demora
Determinación
del tiempo de ciclo óptimo
Se
ingresa en la pestaña ‘Informes’ y se selecciona la sección ‘Optimizar ciclo’.
Posteriormente se cargan los datos de la "Fase", "Sentido",
"Flujo", "Carriles", "FE: Factor de
equivalencia", "q: Flujo vehicular directo", "Y: Flujo de
saturación", "Ymax: Flujo de saturación máxima", "Ysum:
Sumatoria del flujo de saturación", "P: Tiempo total perdido por
ciclo", "Tco: Tiempo de ciclo óptimo", "TV: Tiempo de total
de verde", "TVF: Tiempo de verde de fase", "TA: Tiempo de ámbar
de fase" y "TR: Tiempo de rojo de fase". Además, se puede
habilitar un tiempo de todo rojo a las fases dentro de la intersección con
diferentes valores según la literatura de 0 a 12 s (Ver Figura 9).
Figura 9


Cálculo del tiempo de ciclo
óptimo
DISCUSIÓN
La
selección de las intersecciones, trabajo
de campo, y el control de los tiempos de luces de los semáforos y sus ciclos;
compatibilizan con ALI
et al. (2021) quienes seleccionaron su area de
estudio, considerando la disponibilidad de datos reales, para el control de
señales de tráfico con un método adaptativo; así mismo Celis-Peñaranda
et al. (2016) y Savithramma
et al. (2022), emplearon los datos de las señales,
incluyendo la duración del ciclo en segundos, para el análisis de control
adaptativo; An
et al. (2022) seleccionaron dos intersecciones en
Jungbu-daero en Yongin ciudad con diferentes duraciones de ciclo; concordando
con Zhang
et al. (2021) donde el ciclo de la intersección
entre Fengze Road y Tianan South Road, en la provincia de Fujian tiene un
período de 141 s; al igual que Bashiri (2020) que muestra una
cantidad de 48 segundos para el ciclo del semáforo.
Las variables recolectadas
para la base de datos son similares a las reportadas por diferentes
investigadores, Shaikh
et al. (2022), recogió las siguientes
variables flujo vehicular, tasa del tráfico, longitud de la cola de vehículos,
congestión y el retraso del vehículo para determinar el tiempo de ciclo
mediante algoritmos genéticos. Qian
et al. (2013) y Balaji
et al. (2010), emplearon las variables
número de vehículos, retraso medio y velocidad media actual del vehículo para
crear un modelo con algoritmos genéticos. Wijaya et al. (2019), recolectó las variables volumen de vehículos, duración del verde,
amarillo y rojo, flujo de saturación y equivalente de pasajeros de automóvil
para optimizar la eficacia de la duración de la señal en la intersección. Por
otro lado, Olayode
et al. (2022) utiliza variables de flujo
de tráfico como variables de decisión, para su algoritmo generativo.
El tiempo de ciclo determinado
por el algoritmo son similares a Shelby (2004), quien optimizó el tiempo fijo de Webster, mediante los algoritmos
COP-97 y ALLONS-D, con una precisión del 90% reduciendo la demora del tráfico
en una intersección de los Estados Unidos, Zhang
et al. (2021), mediante algoritmos
genéticos mejorados reduce el retardo de intersección en un 15.64% con alta
precisión. Por otro lado, Support Vector Machine muestra valores más bajos de
0.638 y 0.325, sugiriendo un rendimiento limitado en comparación con
RandomForest. KNeighbors exhibe un desempeño alto con R y R2 de
0.943 y 0.884, mientras que Multi-Layer Perceptron y Gradient Boosting
presentan resultados intermedios con R y R2 de 0.957, 0.893 y 0.983,
0.910, respectivamente, similares a los obtenidos por Shamlitskiy
et al. (2023), quien emplea redes
neurales para optimizar el tiempo de ciclo optimo con una precisión del 90%.
Las
funciones elementales que contiene el programa: ingreso, cálculo e informes de
desarrollo de la intersección semaforizada; son similares a las de Alkandari
et al. (2014) el cual genera un sistema de control
inteligente que se ejecuta mediante software de simulación, permitiendo
opciones que el usuario puede controlar; corrobora con Jiajia & Xingquan (2020) que para su
interfaz gráfica en su intersección única, los vehículos podrán ingresar desde
4 direcciones: este, oeste, sur y norte; similarmente con Doçi
et al. (2022) que en su panel frontal (para su
programa), se encuentra diseñado el tablero de control de intersección con
elementos y variables importantes, en este panel se crean las variables de
entrada/salida necesarias y otros parámetros de control de semáforos.
CONCLUSIONES
Se
identificaron dos intersecciones semaforizadas base en la ciudad de Jaén,
representativas de situaciones reales y actuales. Estas intersecciones fueron
seleccionadas como zonas de estudio, donde se extrajeron y analizaron
detalladamente sus condiciones de señalización, tanto vertical como horizontal,
y de control, incluyendo la configuración de semáforos presincronizados. La
información obtenida se integró en la base de datos y se utilizó para validar
el sistema adaptativo propuesto.
Las
intersecciones formadas por calles y por avenida-calle presentaron
características geométricas basadas en dos carriles, con anchos promedio que
variaron desde 4.44 m a 5.15 m y de 4.36 m a 6.70 m, y pendientes que oscilaron
entre -0.027 y 0.015, y de -0.002 a 0.022, respectivamente. Según el enfoque
tradicional (Webster), se determinó y clasificó cada intersección en su
situación actual, con demoras de 11.41 y 8.32 segundos, y niveles de servicio
"B" y "A", respectivamente.
Con
el empleo de la metodología Knowlegde Discovery Databases (KDD), siendo su
esencialidad la minería de datos, y siguiendo los patrones de sus fases, de los
cinco modelos desarrollados y con el uso de cinco algoritmos de predicción para
el entrenamiento, dos modelos lograron alta precisión empleando el algoritmo
RandomForest con valores R2 de 0.995 y 0.996, para predecir, uno de
ellos tiempo de demora y el otro para tiempo de ciclo óptimo; siendo
sustentables para usarse en la elaboración del programa.
Se
plantearon algoritmos adaptativos que dieron lugar al diseño del programa
"JJ22" en el entorno de Visual Studio Community 2022. Este proceso
incluyó una fase de diseño que abarcó las interfaces gráficas para el inicio,
ingreso de datos, cálculos e informes, y una fase de desarrollo que comprendió
los códigos correspondientes a estas funcionalidades. El programa resultante es
ejecutable y adaptable, ya que calcula y optimiza demoras, ciclos óptimos y
niveles de servicio. Durante las pruebas realizadas en la intersección entre
calles, el programa estimó y redujo los tiempos de ciclo óptimo y semafóricos,
estableciéndolos en 28 segundos para las calles y 25 segundos para la
avenida-calle.
REFERENCIAS BIBLIOGRÁFICAS
Ali, M. E.
M., Durdu, A., Celtek, S. A., & Yilmaz, A. (2021). An
Adaptive Method for Traffic Signal Control Based on Fuzzy Logic With Webster
and Modified Webster Formula Using SUMO Traffic Simulator.
10.1109/ACCESS.2021.3094270
Alkandari,
A., Al-Shaikhli, I. F., & Alhaddad, A. (2014). Optimization of traffic
control methods comparing with dynamic webster with Dynamic Cycle Time (DWDC)
using simulation software. 2014 10th International Conference on Natural
Computation (ICNC), 1071-1076. https://doi.org/10.1109/ICNC.2014.6975989
An, H. K.,
Awais Javeed, M., Bae, G., Zubair, N., M. Metwally, A. S., Bocchetta, P., Na,
F., & Javed, M. S. (2022). Optimized Intersection Signal Timing: An
Intelligent Approach-Based Study for Sustainable Models.
https://doi.org/10.3390/su141811422
Balaji, P.
G., German, X., & Srinivasan, D. (2010). Urban traffic signal control using
reinforcement learning agents. IET Intelligent Transport Systems, 4(3),
177. https://doi.org/10.1049/iet-its.2009.0096
Bashiri, M.
(2020). Data-Driven Intersection Management Solutions for Mixed Traffic of
Human-Driven and Connected and Automated Vehicles.
https://doi.org/10.48550/arXiv.2012.05402
Celis-Peñaranda, J. M.,
Escobar-Amado, C. D., Sepúlveda-Mora, S. B., Castro-Casadiego, S. A.,
Medina-Delgado, B., & Ramírez-Mateus, J. J. (2016). Control adaptativo
para optimizar una intersección semafórica basado en un sistema embebido.
https://doi.org/10.17230/ingciencia.12.24.8
Doçi, I., Duraku, R., & Hoti, B.
(2022). Design Of Traffic Intersection Model And Regulation
With Software And Microcontrollers. https://www.scientificbulletin.upb.ro/rev_docs_arhiva/full1a5_875407.pdf
Jiajia, L.,
& Xingquan, Z. (2020). Research on Fuzzy Control and Optimization for
Traffic Lights at Single Intersection. https://www.china-simulation.com/EN/10.16182/j.issn1004731x.joss.20-FZ0498
Olayode, O. I., Tartibu, L. K., &
Okwu, M. O. (2022, enero 25). Application of Adaptive Neuro-Fuzzy
Inference System Model on Traffic Flow of Vehicles at a Signalized Road
Intersections. ASME 2021 International Mechanical Engineering
Congress and Exposition. https://doi.org/10.1115/IMECE2021-70956
Qian, R.,
Lun, Z., Wenchen, Y., & Meng, Z. (2013). A Traffic Emission-saving Signal
Timing Model for Urban Isolated Intersections. Procedia - Social and
Behavioral Sciences, 96, 2404-2413.
https://doi.org/10.1016/j.sbspro.2013.08.269
Savithramma,
R. M., Sumathi, R., & Sudhira, H. S. (2022). A Comparative Analysis of
Machine Learning Algorithms in Design Process of Adaptive Traffic Signal
Control System. 10.1088/1742-6596/2161/1/012054
Shaikh, P.
W., El-Abd, M., Khanafer, M., & Gao, K. (2022). A Review on Swarm
Intelligence and Evolutionary Algorithms for Solving the Traffic Signal Control
Problem. IEEE Transactions on Intelligent Transportation Systems, 23(1),
48-63. https://doi.org/10.1109/TITS.2020.3014296
Shamlitskiy,
Y., Popov, A., Saidov, N., & Moiseeva, K. (2023). Transport Stream
Optimization Based on Neural Network Learning Algorithms. Transportation
Research Procedia, 68, 417-425. https://doi.org/10.1016/j.trpro.2023.02.056
Shelby, S. G.
(2004). Single-Intersection Evaluation of Real-Time Adaptive Traffic Signal
Control Algorithms. Transportation Research Record: Journal of the
Transportation Research Board, 1867(1), 183-192. https://doi.org/10.3141/1867-21
Wijaya, D. D. A., Luckyarno, Y. F.,
Utami, S. S., & Prasetyo, R. (2019). Analysis of
Vehicle Waiting Time Efficiency Using Webster Method
and Newton’s Divided Difference: Case Study at Mirota Kampus Intersection,
Yogyakarta, Indonesia.
Zhang, H.,
Yuan, H., Chen, Y., Yu, W., Wang, C., Wang, J., & Gao, Y. (2021). Traffic
Light Optimization Based on Modified Webster Function. Journal of Advanced
Transportation, 2021, e3328202. https://doi.org/10.1155/2021/3328202